Chaque chercheur peut créer sa propre échelle, mais cela n'en vaut guère la peine. Il est préférable de choisir une échelle parmi les échelles standards qui sont originales dans le sens où elles ont leur propre nom, sont largement utilisées et sont incluses dans le système d'échelles le plus couramment utilisé. Ils sont aussi appelés originaux. Ensuite, quatre échelles de notation discrètes sont considérées : Likert, différentielle sémantique, notation graphique et Stepel, ainsi qu'une échelle à somme constante et une échelle de classement.
échelle de Likert basé sur le choix du degré d’accord ou de désaccord avec une déclaration spécifique. En fait, un pôle de cette échelle ordinale essentiellement bipolaire est formulé, ce qui est beaucoup plus simple que de nommer les deux pôles. La formulation de l'énoncé peut correspondre au niveau idéal de certains paramètres de l'objet. Lors de la caractérisation du plus haut établissement d'enseignement nous pouvons considérer les propriétés suivantes : personnel enseignant qualifié, équipement de classe moyens techniques, modernité et mises à jour régulières cours de formation, Disponibilité e-leming V technologies éducatives, niveau de culture, image et réputation, population étudiante et bien d’autres. La formulation des déclarations pourrait être la suivante : le personnel enseignant de cette université est très qualifié ; l'université a un très haut niveau d'utilisation des supports pédagogiques modernes ; cette université forme des étudiants en quête de connaissances ; les diplômés de cette université sont très appréciés sur le marché du travail.
Lorsqu’on utilise une échelle de Likert, cinq gradations sont généralement prises en compte. Un exemple d'utilisation d'une échelle de Likert dans un questionnaire est présenté dans la Fig. 8.1. En d’autres termes, les questions sont formulées selon un format d’échelle de Likert. Le répondant est invité à cocher une des cinq cases.
Riz. 8.1.
Dans ce cas, l'évaluation quantitative elle-même n'est pas exigée du répondant, même si le plus souvent des points peuvent être immédiatement attribués à côté des noms des gradations. Comme on peut le voir sur la Fig. 8.1, le degré d'accord ou de désaccord avec chaque affirmation formulée peut avoir les gradations suivantes : fortement en désaccord (1 point), en désaccord (2 points), neutre (3 points), d'accord (4 points), tout à fait d'accord (5 points). Ici, entre parenthèses, se trouve l’option la plus couramment utilisée pour numériser la balance. Il est également possible qu'un score plus élevé (5 points) corresponde à la gradation « pas du tout d'accord ».
Échelle de notation différentielle sémantique et graphique
Échelle différentielle sémantique présuppose la présence de deux sens sémantiques polaires (antonymes) ou positions antonymiques, entre lesquelles il existe un nombre impair de gradations. En ce sens, l’échelle est bipolaire. En règle générale, sept gradations sont considérées. La position médiane (gradation médiane) est considérée comme neutre. La numérisation des gradations d'échelle peut être unipolaire, par exemple sous la forme "1, 2, 3, 4, 5, 6, 7", ou bipolaire, par exemple sous la forme "-3, -2, -1, 0, 1, 2, 3".
Habituellement, les pôles de la balance sont spécifiés verbalement (verbal). Des exemples d'échelles à deux pôles sont les suivants : « apaisant – tonifiant » ou « compact – volumineux ». Parallèlement aux différentiels sémantiques verbaux, des différentiels sémantiques non verbaux ont été développés qui utilisent des images graphiques comme pôles.
Des exemples de différentiels sémantiques verbaux sont donnés dans la Fig. 8.2.

Riz. 8.2.
Le différentiel sémantique ressemble à l'échelle de Likert, mais présente les différences suivantes : 1) les deux énoncés polaires sont formulés au lieu d'un seul ; 2) au lieu des noms des gradations intermédiaires, une disposition graphique séquentielle d'un nombre impair de gradations situées entre les valeurs extrêmes « bon - mauvais » est donnée.
Méthode différentielle sémantique (du grec. sématique – désignant et lat. différence différence) a été proposée par le psychologue américain Charles Osgood en 1952 et est utilisée dans les études liées à la perception et au comportement humains, avec l'analyse des attitudes sociales et des significations personnelles, en psychologie et en sociologie, dans la théorie des communications de masse et de la publicité, et dans commercialisation.
Peut être considéré comme un analogue de l'échelle différentielle sémantique. L'échelle de notation est réalisée de telle sorte que chaque propriété est associée à une ligne dont les extrémités correspondent à des énoncés polaires, par exemple : « pas important » et « très important », « bon » et « mauvais » (Fig. 8.3).
Riz. 8.3.
La différence fondamentale entre les échelles comparées est que la différentielle sémantique est une échelle discrète et, en règle générale, comporte sept gradations et que l'échelle d'évaluation graphique est continue.
- Ainsi, lorsqu'on caractérise l'extérieur de certaines marques de voitures, on dit parfois qu'il se caractérise par la brutalité. Il y en a plus exemples simples– l'ergonomie et la contrôlabilité, alors qu'il est difficile de nommer de manière significative le deuxième pôle.
Cible: se familiariser avec la méthode d'indexation quantitative et qualitative des valeurs et réaliser des exercices pour maîtriser la méthode.
Principes théoriques de base
Selon Charles Osgood, la méthode différentielle sémantique (SD) permet de mesurer connotatif sens, c'est-à-dire les états qui surviennent entre la perception d'un stimulus et un travail significatif avec lui. Connotatif indique quelque chose de subjectif, individuel et précieux, contrasté dénotatif - objectif, interpersonnel, cognitif. Un analogue du concept de « sens connotatif » dans psychologie domestique Le concept de « sens personnel » proposé par A. N. Leontyev peut être envisagé.
Étant une méthode de sémantique expérimentale, la SD, ainsi que d'autres méthodes (par exemple, expérience associative, mise à l'échelle subjective) est utilisée pour construire des espaces sémantiques subjectifs et est largement utilisée en sociologie, en général et la psychologie sociale. S'y tourner dans la recherche psychologique est justifié lorsque nous parlons, par exemple, de l'attitude émotionnelle d'un individu à l'égard de certains objets, que nous étudions les stéréotypes, les idées sociales, la catégorisation sociale, les attitudes, que nous prenons en compte les orientations de valeurs, la signification personnelle subjective et que nous identifions également les théories implicites de personnalité .
SD est une méthode d'étude de cas car elle donne un aperçu du contexte unique de la vie d'un individu. La méthode a été développée par un groupe de chercheurs américains dirigé par Charles Osgood, qui la considérait comme une combinaison de procédures d'association contrôlée et de mise à l'échelle. La méthode SD a attiré l'attention des psychologues nationaux à la fin des années 1970. et, comme l’a noté à juste titre A. M. Etkind, « fait depuis longtemps partie de nos programmes d’éducation psychologique ».
Afin de déterminer la dimension de l'espace sémantique, Charles Osgood a proposé d'utiliser l'analyse factorielle pour établir le nombre minimum de dimensions orthogonales, ou axes. La différenciation sémantique, selon Osgood, implique l'arrangement séquentiel d'un concept dans un espace sémantique multidimensionnel à travers l'une ou l'autre signification entre les pôles de l'échelle. La différence de signification de deux concepts est fonction de la distance multidimensionnelle entre deux points correspondant à ces concepts.
Tout concept au niveau opérationnel peut être représenté comme un point dans l'espace sémantique. Ce point de l'espace sémantique peut être caractérisé par deux paramètres : la direction et la distance au point de référence (c'est-à-dire la qualité et l'intensité). La direction est déterminée par le choix d'une qualité ou d'une autre, et la distance dépend de la valeur choisie sur l'échelle. Plus l’intensité de la réaction est élevée, plus le concept évalué est significatif pour le sujet. Ainsi, chaque concept peut être évalué avec un ensemble d’évaluations différenciantes sur des échelles bipolaires.
Pour se différencier, le sujet se voit proposer un concept (un certain nombre de concepts), ainsi qu'un ensemble d'échelles bipolaires précisées par des adjectifs. Le répondant doit évaluer l'objet différencié sur chacune des échelles bipolaires à sept points proposées. En réponse au mot, le répondant a une certaine réaction qui révèle une certaine similitude avec la réaction comportementale, une sorte de préparation au comportement, quelque chose de médiateur du comportement. Les associations du répondant avec le stimulus sont guidées par des échelles bipolaires données. Les fonctions de ces échelles sont les suivantes : d'une part, elles aident à verbaliser la réaction à un stimulus particulier, d'autre part, elles aident à concentrer l'attention sur certaines propriétés de ce stimulus qui intéressent l'étude, et enfin, avec leur aide, il est possible de comparer les évaluations données par différents répondants sur divers objets.
Objet en cours d'évaluation
|
Lent |
||||||||
|
Petit | ||||||||
|
Passif |
Actif |
La sélection d'une valeur de 0 signifie neutre, 1 signifie faiblela gravité de cette qualité dans l'objet évalué, 2 - degré moyen, 3 - élevé.
Les échelles sont présentées dans un ordre aléatoire, c'est-à-dire que les échelles d'un facteur ne doivent pas être regroupées en blocs. Les pôles de la balance ne doivent pas créer chez le répondant l'attitude selon laquelle le pôle gauche correspond toujours à une qualité négative et le pôle droit correspond toujours à une qualité positive. Le sujet se voit présenter simultanément tous les objets mis à l'échelle, puis il lui est demandé de les évaluer séquentiellement dans les colonnes appropriées, c'est-à-dire que chacun d'eux est placé sur une page séparée avec les échelles correspondantes.
Dans une représentation géométrique, l'espace sémantique peut être désigné par des axes, qui sont facteurs (il y en a trois : évaluation, force et activité), et les significations connotatives des objets sont points de coordonnées ou des vecteurs.
Osgood a mis à l'échelle les concepts de divers domaines et, après avoir effectué une analyse des facteurs et des variances, a identifié les principaux facteurs (évaluation, puissance, activité - EPA). Le facteur d'évaluation a joué un rôle majeur dans cette étude, expliquant 68,6 % de la variance totale, tandis que le facteur d'activité représentait 15,5 % et le facteur de force 12,7 %. La structure factorielle « évaluation - force - activité » définit un champ sémantique universel à l'aide duquel on peut décrire le monde des relations subjectives d'une personne avec les éléments de son environnement.
Facteur d'évaluation combiné les échelles : mauvais - bon, beau - laid, aigre-doux, propre - sale, savoureux - insipide, utile - inutile, gentil - maléfique, agréable - désagréable, doux - amer, joyeux - triste, divin - profane, parfumé - malodorant, honnête - malhonnête, juste - injuste.
Facteur de force : grand - petit, fort - faible, lourd - léger, épais - fin.
Facteur d'activité : rapide - lent, actif - passif, chaud - froid, pointu - brutal, rond - anguleux.
Les données obtenues peuvent être analysées non seulement à l'aide de la procédure d'analyse factorielle, mais également de la formule proposée par Charles Osgood, qui calcule la distance entre les objets mis à l'échelle, c'est-à-dire deux points dans l'espace sémantique. Après tout, les objets à l’échelle peuvent être présentés sous forme de profils sémantiques : des lignes brisées reliant les choix des sujets sur chaque échelle bipolaire (Fig.).
d (x 1, y 1) - la différence entre les coordonnées de deux points qui représentent les valeurs des objets X et V par facteur.
Cette formule permet d'estimer les distances entre les significations de différents concepts pour un même individu ou groupe d'individus, de comparer les appréciations d'un même objet par les répondants, et enfin, d'identifier les changements dans les appréciations de tout objet par un sujet ou un groupe.
SD est une méthode qui permet d'obtenir les informations requises sans utiliser d'objets standards et d'échelles standards. Cela implique qu'« il n'y a pas de « test DM » en tant que tel » ; en fonction des objectifs d'une étude particulière, certains objets et certaines échelles sont sélectionnés qui sont représentatifs et pertinents par rapport aux objectifs. De plus, le chercheur est encouragé à sélectionner des échelles qui semblent adéquates dans chaque cas individuel. Par exemple, il est plus difficile d'évaluer une personne sur l'échelle « aigre-doux », mais plus accessible sur l'échelle « utile - inutile ». Et pour les répondants qui n'ont pas de connaissances particulières dans le domaine de la psychologie ou de la psychiatrie, l'échelle « bavard - silencieux » sera plus compréhensible que l'échelle « maniaco-dépressive ». Chaque facteur doit être représenté par plusieurs paires d'échelles.
Lors de la mise à l'échelle d'un ensemble restreint de concepts, l'espace tridimensionnel « évaluation - force - activité » se transforme et devient unidimensionnel ou bidimensionnel, c'est-à-dire que le nombre de facteurs indépendants est réduit à deux ou un. Il est également possible d'augmenter les facteurs qui décrivent l'espace sémantique multidimensionnel d'un individu ou d'un groupe par rapport à l'évaluation d'un objet.
De telles variantes du SD sont dites privées, contrairement au SD universel unidimensionnel, formé de trois facteurs « évaluation - force - activité ». Si le SD universel nous permet d'obtenir des formes de classification émotionnelles-évaluatives généralisées, alors le SD privé nous permet d'obtenir des classifications sur une base (dénotative) plus étroite. En utilisant le SD universel sur différentes populations, nous obtiendrons trois facteurs indépendants « évaluation - force - activité », et en utilisant le SD privé, nous devons construire des espaces sémantiques privés chaque fois que nous traitons avec un nouveau groupe de répondants.
Une variante du SD privé est le SD personnel, lorsque des échelles bipolaires ou unipolaires sont spécifiées en termes de caractéristiques personnelles (traits de personnalité et de caractère). La procédure du SD personnel est similaire à la procédure du SD universel : un certain nombre d'objets sont évalués sur un certain nombre d'échelles. L'objet de l'évaluation dans ce cas peut être le défendeur ou d'autres personnes. Les données obtenues sont soumises à une analyse factorielle, ce qui permet d’identifier des facteurs qui reflètent la théorie ordinaire de la personnalité de l’individu.
Questions de contrôle
Quels phénomènes mentaux fondamentaux sont sujets à étude par le différentiel sémantique ?
Quelles autres méthodes de psychosémantique expérimentale connaissez-vous ?
Quel est l'espace sémantique du sujet ?
Quelles sont les trois directions orthogonales utilisées pour étudier le champ sémantique des sujets dans le différentiel sémantique ?
Est-il possible d’étudier les similitudes ou les différences dans les profils sémantiques de différentes personnes utilisant SD ?
Quels autres types de méthodes sémantiques différentielles existent en dehors de la méthode universelle ?
Pour vous entraîner à utiliser une différentielle sémantique partielle unidimensionnelle, effectuez les exercices suivants dans l'ordre suggéré ci-dessous.
Exercice 1. Réalisation de la première étape de l'étude. Le but de cette étape de recherche est de sélectionner un sujet de recherche. Pour ce faire, en utilisant une méthode de discussion de groupe, sélectionnez un objet ou une manifestation mentale sur lequel les opinions des élèves doivent être étudiées. Par exemple, 1) les caractéristiques d'un scientifique typique, 2) les propriétés fondamentales de la conscience, etc.
À l’aide d’éléments de la méthode du focus group, mettez en évidence les principales caractéristiques ou propriétés de l’objet. Pour ce faire, chacun écrit 7 à 9 caractéristiques pendant 5 minutes, puis elles sont prononcées à voix haute dans le groupe et ajoutées à la liste générale. Les caractéristiques (au moins 7) qui ont reçu un plus grand nombre de répétitions deviennent la base de la création d'échelles SD.
Dans le cas de l'étude des opinions des répondants de divers échantillons (et pas seulement des étudiants d'un groupe donné) sur l'objet étudié, des entretiens ou des questionnaires peuvent être menés pour collecter des données permettant la formation d'échelles SD.
Exercice 2. L’objectif de la deuxième étape est de constituer une SD privée pour étudier les appréciations des répondants sur les caractéristiques ou les propriétés de l’objet étudié. A. Créer des échelles bipolaires de DM privé basées sur les caractéristiques obtenues à la première étape. B. Utilisez les instructions standard (la version complète des instructions de Charles Osgood est donnée en annexe) ou formulez les vôtres sur cette base. B. Effectuez vous-même une évaluation des caractéristiques du SD privé créé. D. Tracez des lignes reliant vos choix à travers toutes les caractéristiques - créez un profil sémantique individuel.
Exercice 3. La troisième étape de l'étude consiste à créer un profil sémantique de groupe. Pour ce faire, calculez les scores moyens de groupe (par groupe) pour chaque caractéristique, notez-les au tableau, puis transférez ces valeurs dans vos cahiers et superposez-les sur votre profil sémantique individuel.
Exercice 4.Évaluer le degré de similitude ou de différence entre les profils sémantiques individuels et de groupe. Pour ce faire, utilisez la formule des dispositions théoriques. Expliquez les résultats obtenus et tirez des conclusions sur le degré de similitude ou de différence entre les opinions du groupe et les vôtres sur l'objet étudié.
Une personne, percevant n'importe quel objet, le fait par deux canaux. Premièrement, cela donne à l'objet une signification dénotative, c'est-à-dire le sens qu'il a appris au cours de son éducation. Les membres d'une même communauté ont la même signification dénotative d'un même objet. Par exemple, les pommes sont bonnes pour l'homme, contiennent de nombreuses vitamines et ont un bon effet sur le teint. Cette signification sera donnée à la pomme par les communautés dans lesquelles grande importance est donné image saine vie. Une autre communauté peut avoir une perception différente de la pomme : une pomme est un fruit qui doit être stocké au sous-sol dans des caisses avec de la paille et il est conseillé de les utiliser avant le printemps, car... au printemps, ils commenceront à se détériorer. Dans le premier et le deuxième exemple, une personne perçoit la signification d'un objet non pas à travers une « communication » personnelle avec la pomme, mais à partir du processus de socialisation.
En plus de la signification dénotative, chaque objet a une signification connotative pour une personne. Cette signification est personnelle, acquise grâce à une expérience directe. Si par une belle journée ensoleillée une lourde pomme me tombait sur la tête, je perdais connaissance et quand je me réveillais, je réalisais que j'étais allongé dans un tas de bouse de vache, alors pour le reste de ma vie je resterai à l'écart des grappes de grosses pommes sur les arbres. Dans l’exemple donné, l’expérience de « communiquer » avec une pomme est très vivante. Habituellement, le sens connotatif est plus caché.
Je donnerai d'autres exemples de significations connotatives. Le recteur d'une université peut être considéré par ses étudiants comme une personne ferme et froide. Cela ne signifie pas que la densité corporelle et la température du recteur diffèrent de la moyenne des autres personnes en dehors des limites normales.
En d’autres termes, la signification connotative est une émotion envers l’objet évalué.
Qu’est-ce que la sémantique a à voir là-dedans ? Nous introduisons la définition selon Tolstoï. La sémantique est une branche de la linguistique et de la logique qui étudie les problèmes de sens, de signification et d'interprétation des signes et des expressions symboliques. En conséquence, la psychosémantique est l’étude de la perception psychologique par une personne des significations et des significations de divers types d’objets. La psychosémantique comprend des méthodes telles que la différentielle sémantique, les réseaux de répertoire, etc.
La tâche de la psychosématique est très intéressante - la construction d'un espace sémantique J. I.e. système de facteurs latents au sein duquel une personne travaille. Pourquoi avez-vous contourné la flaque d'eau devant l'entrée du côté droit ce matin, alors que c'était plus pratique du côté gauche ?
Pourquoi la sociologie a-t-elle besoin du DD ? Par exemple, un sociologue pourrait essayer d’identifier des types de personnes ayant des perceptions similaires des objets. Si l'objet est le produit annoncé, alors pour chaque type individuel, il est plus efficace de créer une publicité distincte avec la perception souhaitée J
Le gros avantage de la SD est qu’en utilisant des méthodes « dures », elle fournit des informations sur des sujets subtils. structures psychologiques perception humaine des objets.
Technique différentielle sémantique
Qu’est-ce qu’Osgood a suggéré ? L'émotion liée au sens d'un concept sera révélée si une personne indique la position du concept en question dans le système de traits connotatifs. Ceux. indiquera l'emplacement de l'objet dans le système de coordonnées « émotionnel ». Par exemple, taux dirigeant politique: Est-ce qu'il fait chaud ou froid, pelucheux ou épineux ?
Préparons donc plusieurs paires d’émotions (caractéristiques connotatives). Les paires contiennent naturellement des opposés couleurs émotionnelles: aigre-doux, noir-blanc, bien-mal. Chaque paire contient plusieurs gradations. Si vous souhaitez utiliser l'analyse factorielle dans votre analyse, vous avez besoin de données définies par une échelle d'intervalle. Pour ce faire, il doit y avoir sept gradations (plus il y a de gradations, plus votre échelle passe du type ordinal au type intervalle).
| Notez Vassia Pupkin | ||||||||
| lumière | -3 | -2 | -1 | 0 | 1 | 2 | 3 | sombre |
| froid | -3 | -2 | -1 | 0 | 1 | 2 | 3 | chaud |
| calme | -3 | -2 | -1 | 0 | 1 | 2 | 3 | alarmant |
| brouillard | -3 | -2 | -1 | 0 | 1 | 2 | 3 | clair |
| utile | -3 | -2 | -1 | 0 | 1 | 2 | 3 | nocif |
| triste | -3 | -2 | -1 | 0 | 1 | 2 | 3 | content |
| solide | -3 | -2 | -1 | 0 | 1 | 2 | 3 | instable |
| FAUX | -3 | -2 | -1 | 0 | 1 | 2 | 3 | vrai |
| pacifique | -3 | -2 | -1 | 0 | 1 | 2 | 3 | guerrier |
| absurde | -3 | -2 | -1 | 0 | 1 | 2 | 3 | raisonnable |
| Notez Vova Golikova | ||||||||
| lumière | -3 | -2 | -1 | 0 | 1 | 2 | 3 | sombre |
| froid | -3 | -2 | -1 | 0 | 1 | 2 | 3 | chaud |
| calme | -3 | -2 | -1 | 0 | 1 | 2 | 3 | alarmant |
| brouillard | -3 | -2 | -1 | 0 | 1 | 2 | 3 | clair |
| utile | -3 | -2 | -1 | 0 | 1 | 2 | 3 | nocif |
| triste | -3 | -2 | -1 | 0 | 1 | 2 | 3 | content |
| solide | -3 | -2 | -1 | 0 | 1 | 2 | 3 | instable |
| FAUX | -3 | -2 | -1 | 0 | 1 | 2 | 3 | vrai |
| pacifique | -3 | -2 | -1 | 0 | 1 | 2 | 3 | guerrier |
| absurde | -3 | -2 | -1 | 0 | 1 | 2 | 3 | raisonnable |
| Évaluation par Vasya Pupkin | ||||||||||
| clair sombre | froid - chaud | calme - anxieux | brumeux - clair | utile - nuisible | malheureux heureux | dur-instable | faux vrai | paisible - guerrier | insensé - raisonnable | |
| représentant1 | -2 | 2 | 2 | 2 | 0 | -3 | 0 | -3 | 0 | 0 |
| représentant2 | -3 | -1 | 1 | 1 | -1 | -3 | -3 | -1 | -1 | -1 |
| représentant3 | 1 | -3 | -1 | -2 | 0 | -1 | 1 | 2 | -3 | 2 |
| représentant4 | -1 | -2 | -2 | -2 | -3 | -1 | -2 | -2 | -1 | -3 |
| représentant5 | -1 | -2 | -2 | -3 | -3 | -1 | -2 | 0 | -1 | 1 |
| L'évaluation de Vova Golikov | ||||||||||
| représentant1 | -2 | -2 | -1 | 0 | 0 | -2 | -2 | -2 | -1 | -3 |
| représentant2 | -1 | 0 | 1 | -3 | -1 | -1 | 2 | -1 | 0 | -2 |
| représentant3 | -2 | 2 | 1 | 2 | 0 | 1 | 2 | -3 | 1 | 2 |
| représentant4 | 0 | 0 | 2 | -3 | -3 | 0 | -1 | -2 | 0 | -3 |
| représentant5 | -2 | 0 | -3 | -1 | -2 | -1 | 1 | 1 | 0 | -2 |
Osgood a découvert que dans la plupart des cas, l'une des paires connotatives cache l'une des trois options possibles : force, évaluation (attitude), activité. En d'autres termes, si nous prenons un objet, laissons les répondants l'évaluer sur la base de centaines de paires similaires, puis effectuons une analyse groupée de toutes ces paires, nous verrons que toutes les paires sont divisées en trois groupes : force, évaluation, activité. Ceux. Lorsque nous percevons un objet de réalité, nous « attribuons des points » à cet objet selon trois caractéristiques : force (fort-faible), évaluation (mauvais-bien) et activité (rapide-lent).
Le différentiel sémantique (SD) est l'un des méthodes projectives La sociologie, basée sur les acquis de la psychosémantique, a été développée par un groupe de psychologues américains dirigé par Charles Osgood en 1952. Il est utilisé dans les études liées à la perception et au comportement humains, avec l'analyse des attitudes sociales et des significations personnelles. La méthode SD est une combinaison de la méthode d'association contrôlée et des procédures de mise à l'échelle.
Les méthodes psychosémantiques transfèrent l'information du niveau cognitif (et la tâche de recherche est toujours formulée dans ses termes) au niveau affectif, où cette information n'est pas codée par des formes linguistiques, mais par diverses sensations.
La méthode de différentielle sémantique repose sur le phénomène de synesthésie (penser par analogie, lorsque certaines perceptions sensorielles surgissent sous l'influence d'autres) et constitue une manière opérationnelle de « capter » le côté émotionnel du sens perçu par un individu dans les objets. Le SD permet d’identifier des connexions associatives inconscientes entre des objets dans l’esprit des gens.
La méthode SD permet de retrouver un système de facteurs latents dans le cadre duquel un individu évalue des objets. Essentiellement, l'espace sémantique est un modèle de recherche sur la structure de la conscience individuelle, et la tâche est de déterminer où se trouve l'objet étudié dans cet espace.
Les objets testés (nom, marque, emballage, etc.) sont évalués sur plusieurs échelles bimodales à sept points, dont les pôles sont généralement précisés verbalement à l'aide d'antonymes : bon - mauvais, chaud - froid, actif - passif, etc. On suppose qu'une personne est capable d'évaluer l'objet étudié en corrélant l'intensité de l'expérience interne concernant l'objet avec une échelle d'évaluation donnée. Les divisions d'échelle sont fixes divers diplômes qualité donnée de l'objet. Les échelles en corrélation les unes avec les autres sont regroupées en facteurs indépendants qui forment un espace sémantique.
Parallèlement aux différentiels verbaux, des différentiels sémantiques non verbaux ont également été développés, où les oppositions graphiques, les peintures et les portraits photographiques sont utilisés comme pôles d'échelles.
La recherche utilise souvent des échelles monopolaires, à l'aide desquelles les objets sont évalués en fonction de la gravité d'une propriété : la qualité de l'objet, sa chaleur, etc. Dans le cas des échelles bimodales, le répondant évalue où se trouve pour lui l'objet « A » sur l'échelle « cher - bon marché », et avec les échelles unimodales, il évalue à quel point la propriété est « chère » inhérente à l'objet « A ». L'utilisation d'échelles unimodales est due au fait que souvent les adjectifs antonymes ne sont pas en réalité complètement opposés - mauvais n'est pas toujours mauvais.
Dans la version classique de Charles Osgood, des caractéristiques exclusivement connotatives étaient utilisées comme échelles, qui reflétaient non pas les propriétés objectives de l'objet ou du concept évalué, mais les aspects subjectivement significatifs de l'objet ou du concept pour le répondant.
Dans la recherche marketing, un outil reconnu pour étudier l'image d'une entreprise, d'une marque ou d'un produit sont les échelles dénotatives, qui ne sont pas toujours constituées uniquement d'adjectifs antonymes, mais sont, en règle générale, des expressions, des expressions qui expriment des attentes, des caractéristiques du produit, à la fois négatif et positif. Des produits similaires provenant de différentes entreprises manufacturières peuvent être évalués sur une échelle de « valeur pour l'argent », par exemple les banques - en fonction du niveau de fiabilité, de rentabilité, etc.
Pour préserver « l’esprit » de la méthode et capter les éléments encore affectifs de l’attitude, un ensemble d’échelles (15-25 échelles) est utilisé. Le résultat de la technique n'est pas directement calculé les valeurs moyennes des objets sur chacune des échelles, mais des facteurs latents obtenus au cours d'une procédure d'analyse spéciale, sur la base de laquelle l'espace sémantique de perception des objets est formé et une carte de leur les positions relatives sont construites. Il est important de sélectionner un nombre suffisant d'échelles et de les tester sur des experts ou de mener une expérimentation associative sur des représentants groupe ciblé pour éviter le danger de la subjectivité du chercheur lors de la sélection des échelles.
Les échelles SD ne décrivent pas la réalité, mais sont une expression métaphorique des états et des relations du sujet (les instructions que les répondants reçoivent demandent : « Lorsque vous faites des évaluations, soyez guidé par vos propres sentiments et non par vos connaissances »). Dans l’espace de significations affectives qui en résulte, sont enregistrées une convergence de concepts auxquels une personne réagit de manière similaire et une séparation de concepts ayant des arrière-plans émotionnels différents. La distance entre les concepts est exprimée par un certain nombre, qui permet en général de distinguer les appréciations : a) d'un même concept par différents individus (ou différents groupes) ; b) différentes notions le même individu (ou groupe); c) un concept par le même individu (ou groupe) à des moments différents.
Le nombre de facteurs identifiés correspond à la structure de la perception émotionnelle d'une classe d'objets donnée, ainsi, par exemple, lors de l'évaluation d'une banque, seuls deux facteurs peuvent être identifiés : la fiabilité et la rentabilité, tandis qu'une voiture peut être évaluée selon le critères de « fashionabilité, style », « prestige, statut », « prix », « efficacité opérationnelle », « réseaux de service après-vente », etc.
La procédure de développement d'une méthodologie différentielle sémantique au sein d'un domaine spécifique projet de recherche comprend généralement les étapes suivantes :
Formation et test d'une liste d'adjectifs, d'énoncés pour décrire les objets testés (noms, concepts, types de packaging, marques, etc.). Le niveau de conscience auquel le répondant évaluera l'objet mesuré dépend des caractéristiques sélectionnées. En nous concentrant sur les échelles dénotatives, nous élargissons l'espace sémantique, augmentant les informations sur les objets et perdant inévitablement des informations sur les sujets, ce qui n'est pas si critique dans la recherche marketing.
Traitement mathématique de la matrice de données résultante : objet - répondant - échelle. Généralement, une procédure d'analyse factorielle est utilisée, qui permet d'identifier des critères d'évaluation latents dans lesquels s'ajoutent les échelles initiales. Il est important de noter que pour obtenir des résultats significatifs, des échantillons relativement petits - 30 à 50 personnes - suffisent, du fait que l'unité d'analyse n'est pas le répondant, mais les notes qu'il attribue aux objets. Considérant que chacun des 30 à 50 répondants évalue 7 à 10 objets sur des échelles de 15 à 25, la taille totale de l'échantillon s'avère tout à fait suffisante pour tirer des conclusions statistiquement significatives.
Placement des objets évalués dans l'espace sémantique construit, analyse de la distribution résultante. Estimation de la distance entre les objets testés et l'objet idéal (par exemple yaourt idéal, voiture, « moi-même », etc.), pour déterminer les pôles « positifs » des facteurs. Par exemple, si nous avons reçu le facteur « tendance, style, luminosité » d'une voiture, il est alors important de comprendre si les notes élevées de notre marque sur ce facteur sont positives ou non pour le public cible. Peut-être que la voiture idéale pour eux est un « cheval de fer » fiable et conservateur, économique en consommation de carburant et sans particularités particulières dans la conception.
Étape 1 Formation et test d'une liste d'énoncés.
Les outils utilisés dans la technique différentielle sémantique consistent généralement en un tableau du type suivant : les échelles sont placées dans les lignes, et les objets évalués sont placés dans les colonnes. Les instructions proposées au répondant sont formulées approximativement comme suit : « Veuillez évaluer les caractéristiques de chacune des marques « … » sur une échelle de 0 à 5, où 0 signifie aucune propriété de ce type et 5 signifie que la propriété est exprimée au maximum. . Dans la colonne « idéal… », notez quelles propriétés un bon… devrait avoir, en utilisant une échelle de 0 à 5, où 0 - une telle propriété ne devrait pas exister et 5 - la propriété devrait être inhérente au produit. dans toute la mesure du possible. »
Considérant qu'un échantillon tout à fait suffisant pour un groupe homogène de répondants dans le cadre de cette méthodologie est de 30 à 50 personnes, il est souvent pratique de collecter des informations en parallèle d'une étude de groupe de discussion. Considérant qu'habituellement le lancement d'une nouvelle marque, d'un nouveau nom ou d'un nouveau packaging s'accompagne d'une série de groupes de discussion, alors au cours de 3 à 5 groupes, il est possible de collecter 30 à 50 questionnaires. Cette taille d'échantillon s'avère tout à fait suffisante pour compléter les informations conscientes et rationnelles fournies par les répondants par des évaluations des éléments affectifs de l'attitude, c'est-à-dire collecter des données extraconscientes, émotionnelles, irrationnelles que la technique différentielle sémantique permet d'obtenir.
Figure 4 - Exemple de table différentielle sémantique pour l'évaluation d'objets
Étape 2. Traitement mathématique des résultats et leur interprétation
La technique SD permet de traiter assez clairement les résultats et de les interpréter à l'aide des caractéristiques statistiques les plus simples. La valeur moyenne de la valeur mesurée, l'écart type et le coefficient de corrélation sont proposés comme caractéristiques. Le traitement primaire des résultats consiste à établir une série statistique de la valeur mesurée pour chaque objet étudié. Ensuite, la valeur statistique moyenne de la valeur mesurée pour l'échantillon et une mesure de l'unanimité des estimations, exprimée par l'écart type, sont calculées. Une fois identifiées les notes moyennes de chaque objet pour les trois indicateurs mesurés, il est intéressant de retracer leur interdépendance. Donc l'algorithme traitement mathématique Les résultats SD sont les suivants :
Étape 1. Etablissement d'une série statistique sous forme de tableau.
X i - évaluation d'une certaine qualité d'un objet sur une échelle de sept points ;
n i - fréquence de la valeur X i, c'est-à-dire combien de fois le score X i a-t-il été attribué lors de l'évaluation de l'objet en fonction du paramètre étudié par tous les répondants dans leur ensemble.
Étape 2. Calcul de la valeur moyenne.
Si K répondants ont participé à l'enquête, alors la valeur moyenne est calculée à l'aide de la formule :
n=M*K, puisque la qualité étudiée est évaluée K par les répondants sous la forme développée M fois (en M paires d'adjectifs antagonistes). La valeur moyenne de X sert d'indicateur de l'appréciation globale d'une qualité donnée d'un objet par l'ensemble de la classe, étant en même temps une caractéristique assez objective, puisqu'elle permet de neutraliser l'influence facteurs subjectifs(par exemple, biais des répondants individuels envers un objet donné au moment de l'enquête).
Étape 3. Calculez l’écart type.
L'écart type sert d'indicateur de la mesure de dispersion des valeurs d'une grandeur autour de sa valeur moyenne X, c'est-à-dire mesures d'unanimité et de cohésion des répondants dans l'évaluation d'une qualité donnée d'un objet. L'écart type est calculé comme la racine carrée de la variance y x = vD x, où la variance D x, à son tour, est calculée par la formule :
Les trois étapes décrites du traitement mathématique des données de diagnostic révèlent l’image de la perception des objets étudiés par les répondants. Cela vous permet de présenter clairement les résultats de l’analyse.
Les données obtenues après le traitement décrit ci-dessus peuvent être comparées entre elles en calculant leur corrélation. Cette étape de traitement vise à établir dans quelle mesure l’attitude des répondants à l’égard de l’objet est liée à ses caractéristiques individuelles.
Étape 4. Calcul de la corrélation des estimations obtenues.
Lors de la détermination du coefficient de corrélation, la valeur moyenne des notes de chacun des indicateurs pour tous les objets évalués est d'abord calculée. Disons qu'un répondant évalue n objets. En fonction de l'activité, le 1er objet a été évalué par la valeur moyenne de A j. Puis le score moyen de l'indicateur A de tous les objets :
Score moyen de l’indicateur P :
Alors le coefficient de corrélation de A et P r A,P :
(covariance); , - les écarts types des valeurs A j et O j par rapport à leurs valeurs moyennes, qui se retrouvent comme suit :
Suite au calcul de la corrélation des estimations, vous pouvez clairement voir mécanisme psychologique construire le rapport entre les appréciations des répondants et les objets étudiés.
Étape 3. Présentation de la localisation des marques testées dans l'espace sémantique.
Après l’étape de traitement mathématique, plusieurs facteurs principaux peuvent être identifiés et la localisation des marques testées dans l’espace sémantique formé par les facteurs latents identifiés peut être présentée.
Les résultats s'avèrent finalement assez visuels et assez faciles à interpréter : la figure montre qu'un produit idéal devrait avoir haute qualité et un prix acceptable (pour la clarté de l'exemple, des propriétés plutôt évidentes ont été sélectionnées). En termes de facteur qualité, les marques 1 et 2 sont les plus proches du produit idéal, et en termes de facteur prix, les marques 4 et 5. En évaluant l'ensemble des critères, on peut conclure que la marque 1 est la plus proche de l'idéal.
De la même manière, vous pouvez tester, par exemple, des options de nom, en choisissant des noms qui évoquent les émotions les plus positives, tout en étant associés à un produit spécifique et en évoquant une image et une association avec les qualités précieuses correspondantes.
Des résultats intéressants peuvent être obtenus en comparant des produits qui ne sont pas en concurrence les uns avec les autres, mais qui ont une base similaire, ce qui rend la comparaison possible et aide à identifier de nouvelles qualités évaluées positivement d'un produit ou d'une marque et à les transférer dans un nouveau domaine de produit (invention pour utiliser).
Par exemple, l'évaluation cartes en plastique en général, afin de comprendre quelles propriétés des cartes carburant en plastique doivent être développées et dont l'utilisation contribuerait à conquérir le marché des cartes carburant.
La technique différentielle sémantique permet, lors de l'étude d'une marque, d'identifier une attitude émotionnelle à son égard (la composante affective de l'attitude), non alourdie par des motivations rationalisantes (l'aspect cognitif). Identifiez ce que le consommateur potentiel pense de la marque, c'est-à-dire prédire son comportement réel, et non des mots sur ses actions.
Le différentiel sémantique vous permet de tirer des conclusions statistiquement significatives sur de petits échantillons (un matériel suffisant peut être collecté à partir de 3 à 5 groupes de discussion homogènes) du fait que l'unité d'analyse n'est pas le répondant, mais l'évaluation (en moyenne, chaque répondant évalue 7 à 10 objets sur 15 à 25 échelles, c'est-à-dire donne 100 à 250 notes).
La méthode SD permet d'identifier la structure des facteurs latents, critères sur la base desquels les répondants construisent des évaluations de différentes marques. Ainsi, grâce à la méthode SD, il est possible de construire une carte du placement des marques d'intérêt dans la structure des facteurs, obtenant ainsi un résultat de recherche visuel et relativement facile à interpréter.
L'utilisation d'un objet « idéal » dans la méthodologie SD, ainsi que des marques testées, permet de déterminer les orientations de développement souhaitées, les menaces possibles pour la marque et les propriétés les plus significatives (bien que parfois inconscientes du consommateur) de le produit.
L'utilisation de la méthodologie SD dans la recherche marketing permet d'évaluer une marque et ses éléments (nom, emballage, identité d'entreprise, etc.), en obtenant des estimations statistiquement significatives des structures profondes de la conscience des consommateurs au cours d'une période relativement peu coûteuse et petite. -étude à grande échelle.
B.P. Gromovik, A.D. Gasyuk,
L.A. Moroz, N.I. Chukhrai
Utiliser le différentiel sémantique dans la recherche marketing
Université médicale d'État de Lviv nommée d'après. Danil Galitski
Université d'État "Polytechnique de Lviv"
DANS conditions modernes Le besoin d’informations marketing ne cesse de croître et les responsables marketing manquent de données fiables, pertinentes et complètes. Pour résoudre ce problème, les entreprises pharmaceutiques doivent créer un système de collecte des informations marketing nécessaires - un système d'information marketing.
Il existe quatre sous-systèmes principaux pour la collecte, le traitement, l'analyse et la recherche d'informations marketing, à savoir :
| un sous-système de reporting interne d'une entreprise pharmaceutique, qui permet de suivre des indicateurs reflétant les niveaux de ventes, les coûts, les volumes de stocks, les flux de trésorerie, les données sur les comptes clients et fournisseurs, etc. | |
| sous-système de collecte d'informations marketing externes actuelles, c'est-à-dire un ensemble de sources et de procédures utilisées pour obtenir des informations quotidiennes sur les différentes tendances du marché ; | |
| un sous-système de recherche marketing pour concevoir, collecter, traiter et analyser des données qui nécessitent une recherche spéciale sur un problème de marketing spécifique ; | |
| sous-système de marketing analytique, composé d'une banque de statistiques et d'une banque de modèles mathématiques et couvrant des outils avancés d'analyse des données et des situations problématiques. |
Si les informations externes et internes accumulées systématiquement dans un système d'information marketing grâce à la surveillance du marché s'avèrent insuffisantes, il est nécessaire de mener des études spéciales sur divers problèmes de marketing.
Processus recherche en marketing se déroule en plusieurs étapes (Fig. 1).

Riz. 1. Processus d'étude de marché
Dans un premier temps, il est nécessaire de déterminer le sujet de la recherche et les objectifs, qui doivent être clairement définis et réalistes.
Les objectifs de l'étude peuvent être :
Il existe deux types d’informations marketing collectées au cours du processus de recherche :
La recherche commence principalement par la collecte d’informations secondaires. Cette étape est appelée recherche « documentaire ». Les informations secondaires peuvent être collectées à partir de sources internes et externes.
Dans la plupart des cas, la recherche marketing, après avoir traité et analysé les informations secondaires, procède à la collecte de données primaires, ce qui nécessite une préparation minutieuse. Le plan de collecte d'informations doit principalement déterminer la méthode de recherche. Les méthodes de recherche les plus utilisées sont présentées dans la Fig. 2.

Riz. 2. Méthodes de collecte d'informations primaires
L'observation est une méthode analytique avec laquelle le chercheur étudie le comportement des consommateurs, des vendeurs ; parfois, il participe à des événements (observation active).
Une enquête consiste à connaître les positions des personnes, leurs opinions sur certains problèmes en fonction de leurs réponses à des questions préparées à l’avance.
Un type d'enquête est un entretien approfondi, utilisé pour étudier le comportement du consommateur et sa réaction à la conception ou à la publicité d'un produit.
Si l’étude de marché est insuffisante, il faut :
Le plus souvent utilisé :
- panel commercial (en particulier panel de vente au détail) ;
- panel de consommateurs (consommateurs finaux ou organisations de consommateurs).
Expérience - une méthode avec laquelle vous pouvez étudier (découvrir) la réaction du groupe de personnes étudié à certains facteurs ou à leurs changements. L'expérience vise à établir des relations de cause à effet entre les variables étudiées en testant une hypothèse de travail.
Imitation - une méthode basée sur l'utilisation d'ordinateurs et l'étude des relations entre différentes variables marketing à l'aide de modèles mathématiques appropriés, plutôt qu'en conditions réelles. Il est utilisé assez rarement.
La méthode la plus courante est l’enquête, qui est utilisée dans environ 90 % des études de marché.
En règle générale, un outil courant pour collecter des données primaires est un questionnaire. Lors de l'élaboration des questionnaires, deux types de questions sont utilisées : ouvertes et fermées. Une question ouverte donne au répondant la possibilité de répondre avec ses propres mots. Les réponses à ces questions sont plus informatives, mais elles sont plus difficiles à traiter.
Une question fermée contient des options de réponse possibles et le répondant en choisit une. Les formes de questions fermées peuvent être différentes. Les plus courantes sont les questions alternatives (en supposant des réponses « oui » et « non ») et les questions à réponses sélectives. Assez souvent, les chercheurs utilisent différentes échelles, notamment :
Les étapes de la recherche marketing utilisant le différentiel sémantique sont présentées dans la Fig. 3.
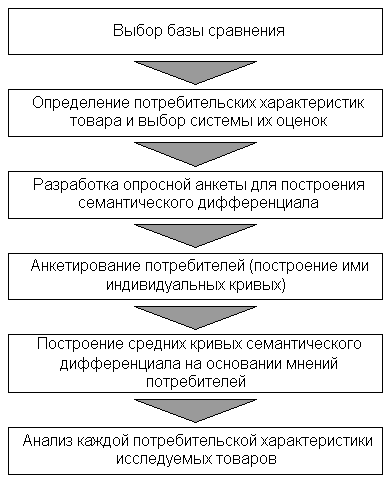
Riz. 3. Étapes de la recherche marketing utilisant le différentiel sémantique
Dans un premier temps, il est nécessaire de sélectionner une base de comparaison, c’est-à-dire le produit d’un concurrent qui présente la plus grande menace pour l’entreprise étudiée et qui est le plus représentatif sur le marché. Ensuite, les caractéristiques de consommation de cette catégorie de produits qui sont les plus importantes pour le groupe cible de consommateurs étudiés sont déterminées et un système d'évaluation de ces caractéristiques est sélectionné. Ensuite, un questionnaire est élaboré pour construire un différentiel sémantique. L’étape suivante est une enquête auprès des consommateurs interrogés, c’est-à-dire leur construction de courbes différentielles sémantiques, guidées par la perception des caractéristiques du produit étudié, du produit concurrent de base et de l’hypothétique produit idéal. La recherche marketing est complétée par la construction de courbes moyennes basées sur les avis des consommateurs et l'analyse de chaque caractéristique de consommation des produits étudiés.
A titre d'exemple, nous avons choisi le shampooing « Magic of Herbs » comme objet d'étude marketing, produit par l'usine pharmaceutique Nikolaev et la JV LLC « Magic of Herbs ». La base de comparaison était le shampooing Elseve produit par la société française L’oréal.
Ces produits ont été examinés selon 10 caractéristiques du consommateur, qui ont été évaluées sur une échelle de 10 points (tableau). Les répondants ont évalué chaque élément du questionnaire avec un score correspondant pour le shampooing « Magic of Herbs », « Elseve » et le shampooing idéal qu'ils aimeraient acheter.
Tableau. Différentiel sémantique des caractéristiques des consommateurs des shampoings « Magic of Herbs », « Elseve » et du shampoing idéal 
Sur la base des données obtenues, des profils moyens de trois courbes ont été construits, qui reflètent la perception subjective moyenne des caractéristiques du consommateur des produits étudiés et la vision du shampooing idéal.
En analysant les courbes (tableau), il convient de constater que le shampooing étudié « Magie des Herbes » satisfait les consommateurs cibles selon les caractéristiques suivantes : odeur agréable ; effet de pureté et de brillance soyeuse ; marque de produit relativement connue et présence d'ingrédients naturels ; prix (inférieur au shampoing Elseve).
Dans le même temps, les consommateurs ne sont pas entièrement satisfaits de l'emballage du shampooing Magic of Herbs, en particulier de son design et de sa commodité, ainsi que de l'absence de revitalisant. Par conséquent, nous pouvons recommander au fabricant d'accorder plus d'attention à l'amélioration de l'emballage et à la combinaison du shampooing avec d'autres composants (après-shampooing, kératides, etc.). Il convient de prêter attention à la disponibilité de quantités suffisantes de shampoing dans le réseau de vente au détail en tant que facteur de disponibilité de son achat.
Ainsi, l’utilisation du différentiel sémantique dans les études marketing permet une différenciation approfondie et visuelle des caractéristiques des produits comparés. De plus, cela permet d'identifier les besoins des différentes catégories de consommateurs avant de choisir la place d'un produit sur le marché, puisque le consommateur perçoit tout produit comme un ensemble de certaines caractéristiques et, en fonction de leur ensemble optimal, privilégie un produit plutôt qu'un autre. .
Littérature
- Kovalenko M. // Informations commerciales. - 1997. - N° 1. - P. 59-62.
- Kutsachenko E. //Entreprise.- 1999.- N° 31 (342).- P. 40-41.
- Mnushko Z. M., Dikhtyarova N. M. Gestion et marketing en pharmacie. Deuxieme PARTIE. Marketing en pharmacie : Pidr. pour l'industrie pharmaceutique universités et facultés / Éd. Z. M. Mnushko.- Kharkiv : Osnova, UkrFA, 1999.- P. 237-241.
- Starostina A.O. Recherche marketing. Aspect pratique - K. ; M. ; SPb : Vue. maison "Williams", 1998.- 262 p.
























